
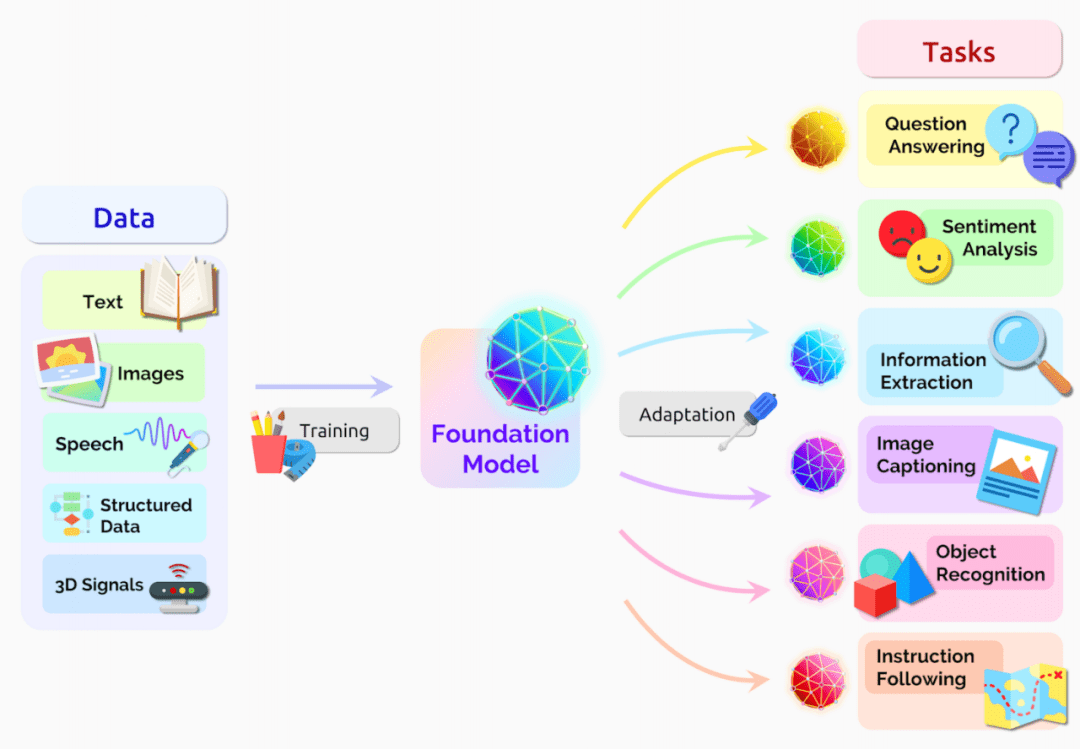
几乎每一个行业都在讨论大模型,每一个行业巨头都在训练大模型,人工智能已然进入了大模型主导的时代。
想要占领大模型应用的高地,数据和算力可以说是不可或缺的基石。和算力相关的讨论已经有很多,以至于英伟达的市值在2023年翻了两番。同样不应小觑的还有数据,除了数据量的爆炸性增长,数据的读取、写入、传输等基础性能,开始遇到越来越多的新挑战。
01 “榨干”算力必须迈过的一道坎
在许多人的认知里,训练大模型是一门烧钱的生意。坊间传闻,GPT-4的训练成本高达10亿美元,想要让大模型释放出应有的“魔法”,“涌现”出对答如流的能力,需要一只“独角兽”的前期投入。
再具体一些的话,大模型训练的成本构成中,硬件投资包括算力、运力、存力,其中算力相关硬件投资占比80%。毕竟一颗80GB的A100芯片在国外的定价就高达1.5万美元左右,一个千亿级参数的大模型,往往需要上万颗A100的算力。可在现实的训练过程中,GPU的平均利用率却不足50%,制约因素包括大模型参数需要频繁调优、训练中断后恢复周期长、数据加载速度慢等等。
不客气的说,算力资源闲置的每一分钟都是在燃烧经费,倘若可以进一步提高算力资源的利用率,等于间接降低了大模型的训练成本。要提到算力利用率,必须要迈过的一道坎就是数据读写性能的挑战。
大模型在训练过程中,需要先读取一块数据,在数据读取完成后进行训练,训练过程中会读取下一块数据。如果训练结束时下一块数据没有读取完成,就会造成一定的等待时间。再加上网络波动、算力故障导致的训练中断,即Checkpoint时刻,重启训练会退回到前一个节点,同样会产生算力空置的等待时间。
不那么乐观的是,目前的训练数据通常以图片、文档等小文件的形式存在,意味着在训练过程中需要频繁地读取和写入数据,并且需要支持快速地随机访问。何况大模型训练的原始数据集动辄几十个TB,当前文件系统的小文件加载速度不足100MB/s,无形中限制了整个系统的运转效率。
根据第一性原理,大模型训练时算力利用率低的诱因是海量的小文件,传统存储系统无法高效地处理这些数据,导致加载速度缓慢。大模型训练的效率要达到极致,减少不必要的浪费,必须在数据上下功夫,准确地说,必须要在数据存储性能上进行创新。
而华为在高性能NAS存储上深耕多年,其OceanStor Dorado全闪存NAS拥有业界领先性能,尤其在海量小文件场景,性能做到了领先业界30%。
在openEuler开发者大会2023上,华为还携手openEuler发布了NFS+协议,矛头直指客户端访问OceanStor Dorado NAS的性能,试图通过引入外置高性能并行文件存储系统,缩短大模型训练中的等待时间,尽可能把算力的价值“榨”出来。
02 华为NFS+协议带来的“屠龙术”
揭开华为NFS+协议的“面纱”前,似乎有必要回顾下NFS协议的历史。作为Sun公司在1984年开发的分布式文件系统协议,NFS已经存在了近40年,广泛应用于金融、EDA仿真、话单、票据影像等行业。
只是在时间的推移下,“老将”NFS逐渐暴露出了一些短板。比如传统NFS单个挂载点仅指定一个服务端IP地址,在网口故障或者链路故障场景下,可能出现挂载点无法访问的情况;一端故障时IP无法感知时,仅依靠应用层手动挂载文件系统,双活链路无法自动切换;单个挂载点性能受限于单个物理链路性能,重要业务存在性能瓶颈。
大约在两年前,华为开始了NFS+协议的研发,着力解决传统NFS的不足,最终交出了一份“高可靠高可用”的答卷:
一是可靠性。打个比方的话,传统NFS的客户端和服务端之间仅有一条路,NFS+协议允许单个NFS挂载点使用多个IP进行访问,等于在客户端和服务端之间修了多条路,巧妙解决了传统NFS被诟病的“可靠性”问题。
二是多链路聚合。客户端和服务端之间仅有一条路时,一旦出现事故就会导致交通拥堵;而NFS+协议在选路算法的加持下,实现了单个挂载点在多条链路上均衡下发IO,确保服务端和客户端的数据传输畅通无阻。
三是缓存加速。大模型训练时,需要将元数据缓存到计算节点。传统NFS相对保守,缓存过期的时间比较短。而NFS+协议改善了缓存大小和失效机制,可以让元数据更多、更长时间保存在主机侧,以满足大模型训练的高时延需求。
四是数据视图同步。正如前面所提到的,大模型训练需要快速的随机访问,NFS+协议采用了数据视图同步的方式,大模型训练需要读取某个节点的数据时,直接与对应节点高效地放置和访问数据,找到最优的访问链路。
做一个总结的话,NFS+协议采用了高性能并行文件存储系统的设计,针对海量小文件场景进行了特殊优化,比如多链路聚合、缓存加速、数据视图同步等,均在提升海量小文件的读写性能,最终在大模型训练过程中实现“读写快、少等待”,减少算力的空置时间。
一组Client测试数据印证了NFS+协议的路线正确:相较于传统的文件存储,训练样本小IO随机读性能提升了4倍以上,CheckPoint大文件切片+多路径传输提升了4-6倍的带宽能力,足以满足大模型训练的苛刻要求。
03 数据存储进入到“大模型时代”
某种程度上说,大模型训练催生的数据存储性能要求,不过是文件存储系统加速演变的一个侧面。
直到今天,文件存储的需求仍在不断更新,文件系统的创新也在持续发生,就像大模型训练需求所折射出的演进方向。
要知道,英伟达的一个训练节点,每秒就可以处理2万张图片,每个节点需要8万IOPS,大模型典型配置有是千亿参数千卡,单位时间内对海量小文件的读写频率要求极高。
这恐怕也是华为和openEuler联合发布NFS+协议的原因,市场对于文件系统的创新需求骤然加快,势必会引发头部科技企业围绕数据存储的“军备竞赛”,华为无疑是这场竞赛中冲在最前面的玩家之一。
但对文件存储系统的市场格局稍作了解的话,华为自研NFS+协议,还隐藏着另一重深意。
一方面,Lustre、GFPS、BeeGFS等并行系统的MDS方案,将元数据和文件数据访问分开,仍存在性能和可靠性的瓶颈;而NFS+协议的元数据不再聚焦于某个性能节点,而是分配到集群的所有节点里面,可以在主机侧实现多连接,消除了大模型语境下高频处理小文件的底层瓶颈。
另一方面,站在大多数用户的角度上,NFS+协议可以更好的兼容已有的使用习惯,原先建立在传统NFS上的运维机制和知识体系不作废,文件系统的切换过程更平缓,不用修改操作系统数据面,即可让NAS存储访问性能提升6倍、可靠性提升3倍,以极低的成本拥抱大模型训推浪潮。
无可否认的是,大模型正在从前台的“火热”,转向整个产业链条的协同驱动,数据存储正是其中的关键一环。
在这样的趋势下,行业注意力将从“炼模”一步步转向更高效、更快速的“炼模”,海量小文件的采集和加载性能、算力资源的利用率等指标,将被越来越多的企业所关注,势必会掀起一场化繁为简的文件存储革命。
