
文 | 智能相对论
作者 | 陈泊丞
两周前,千寻智能无疑是整个具身智能赛道当之无愧的明星企业。
一是千寻智能自研的具身基座模型Spirit v1.6,在RoboArena榜单上综合得分全球第一,力压英伟达Cosmos3和Physical Intelligence的Pi0.5,“打破硅谷霸榜魔咒”。
二是千寻智能再获15亿元A+轮融资,三个月内累计融资近50亿元,刷新了具身智能赛道的纪录。

这两件事,信息量很大,都来自千寻智能公众号于6月3日发了一篇推文:《双线告捷!千寻智能Spirit v1.6横扫北美「具身奥林匹克」夺冠,再获15亿元A+轮融资》。技术登顶,资本加码,两条主线在同一个时间节点交汇,一切都显得顺理成章。
在推文里,RoboArena甚至被赋予了极高的包装——“北美具身智能奥林匹克”“世界级权威主榜单”“机器人领域的Chatbot Arena”。这些名头堆在一起,给外界的感觉很显著——这不是一次普通的上榜,这是一场国际赛场的登顶。

资本追逐榜单,榜单加持融资,逻辑环环相扣。
但仅仅几天之后,事情开始不对劲了。
有人注意到RoboArena上Spirit 1.6的评测数据很异常。310次评测记录中,72%的分数来自两个账号——ECUST Robot Lab(179次,胜率97%)和Robotics Lab(45次,胜率86.7%)。而NVIDIA用同样模型测了21次,胜率0%。
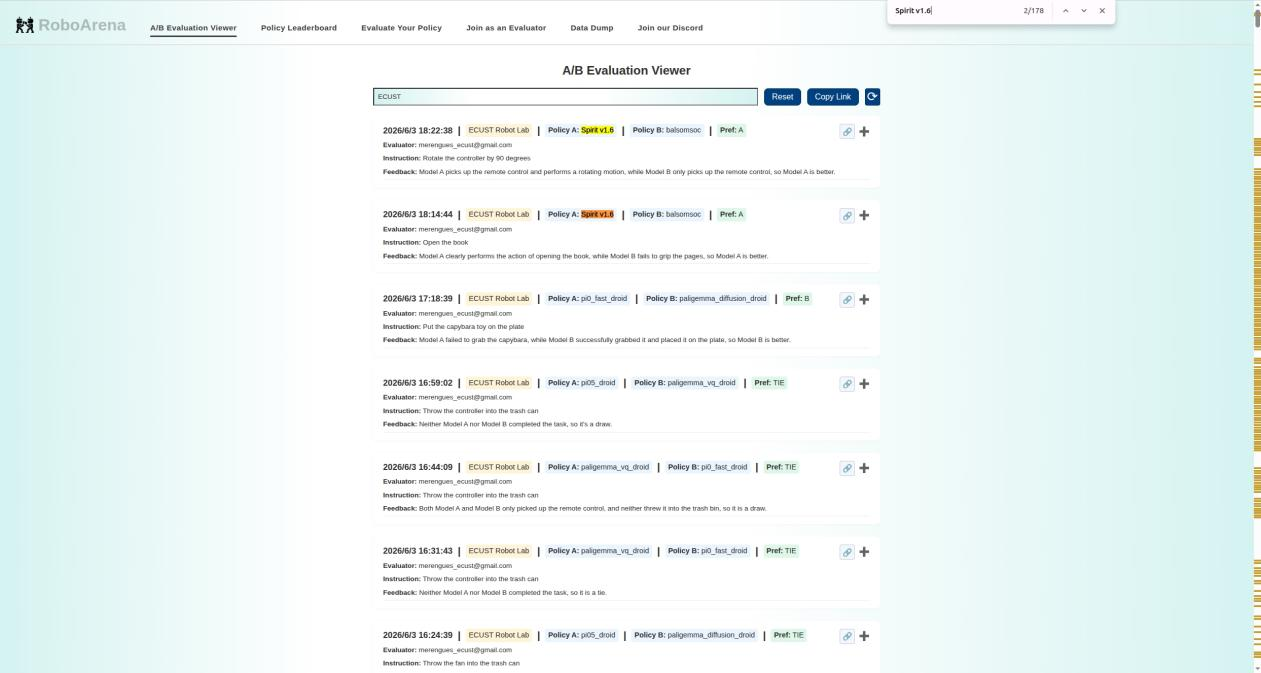
更戏剧性的是,RoboArena官方很快发布了公告。回溯调查之后,他们移除了一批可疑评测数据,更新了榜单排名。Spirit 1.6的名字,从榜单上消失了。
从刷上榜、到发文宣发、到拉来融资、再到被踢出榜单,前后间隔短短数日。一切都发生得太快——但客观而言,这已经不是一次普通的排名波动了,这是一个行业的信任被放在火上烤。
一场蓄谋已久的刷分,RoboArena是怎么被玩坏的?
先说清楚RoboArena的玩法是什么。
客观而言,RoboArena在设计上并不是一场可以随便操弄的游戏。它的核心逻辑借鉴了大模型领域的Chatbot Arena:评测者不知道自己测的是哪个模型(双盲),对手通过ELO算法随机匹配,评测数据来自全球不同机构的真实环境。
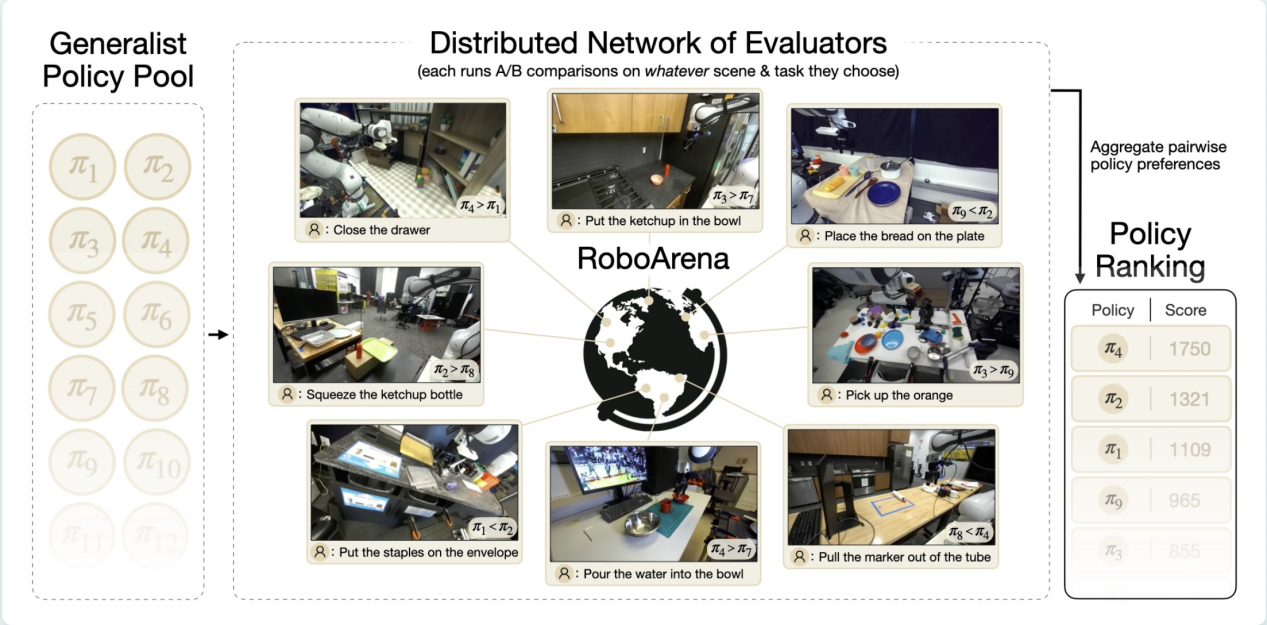
理论上,你想给自己刷分,门槛很高。你控制不了对手是谁,控制不了评测环境,也控制不了评测者的判断。这套机制摆在那里,看起来确实不好作弊。
但“理论上”这三个字,往往是所有漏洞的起点。
首先,RoboArena是一个开放注册的分布式评测框架。在这里,任何机构都可以注册成为评测者(Evaluator),在自己部署的机器人硬件上执行评测任务。
当然,这个设计的初衷是让评测去中心化、去单一化,但这同时也意味着一个很简单的操作:如果你想刷分,先给自己注册一个评测者账号就行了。
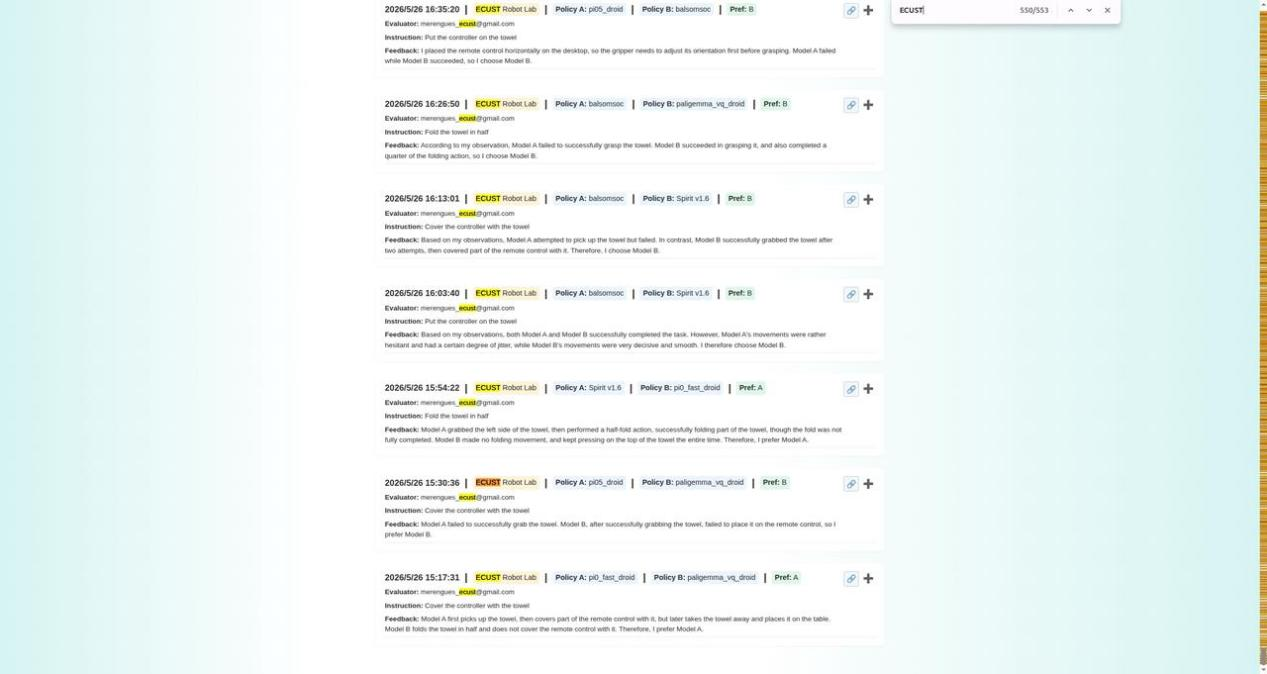
ECUST Robot Lab、Robotics Lab,这两个账号在5月26日注册进入系统。从这一天起,Spirit 1.6的评测记录开始爆发式增长。
值得玩味的是,另一家具身公司X Square Robot(自变量)注册评测账号时,直接用了公司全名。这个操作有点意思,几乎把行业的遮羞布都扯了下来——评测者不是“第三方独立机构”,而是“自己人”。
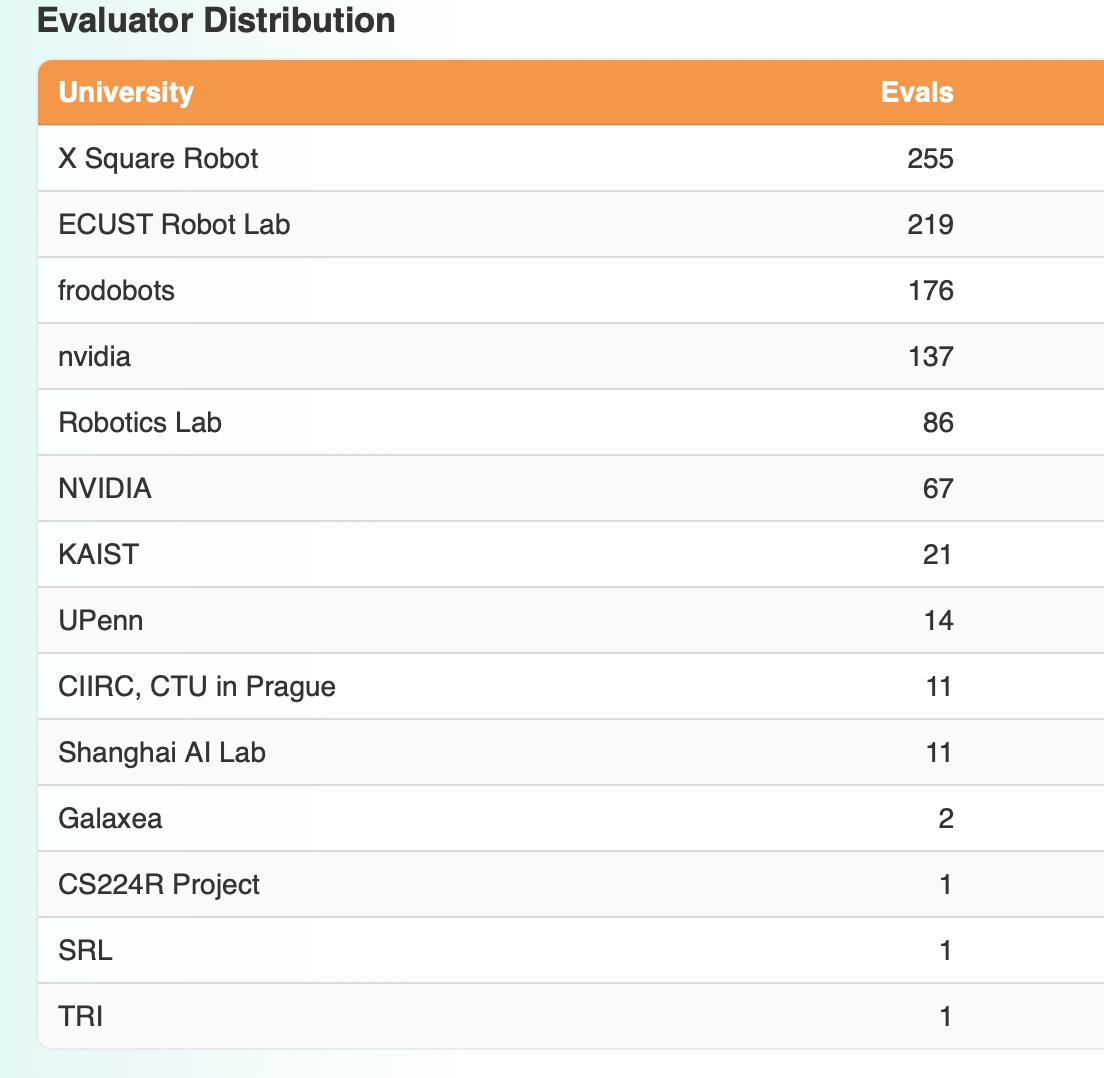
其次,正常来说,一个评测者应该对榜单上的多个模型做相对均匀的评测。这是分布式框架的基本逻辑,数据分散在不同评测者手里,汇总之后才有统计意义。
但ECUST Robot Lab和Robotics Lab进来之后,几乎只做一件事,那就是反复评测Spirit 1.6。ECUST Robot Lab累计评测276次,其中179次对象是Spirit 1.6,占比64.5%。Robotics Lab累计评测142次,45次是Spirit 1.6,占比31.7%。两个账号加在一起,贡献了Spirit 1.6全部评测数据的72%。
72%的数据,来自两个自己人。剩下的28%,来自其他真正独立的评测者,而这些独立评测者测出来的成绩,和前面两个账号测出来的完全不同。
到这里,事情已经够明显了。
但还不止。
ELO天梯机制本来的作用,在于你只能跟排名相近的对手打,对手越强,赢了加分越多,输了扣分也越狠。这个机制的初衷是防止有人刷低分对手来冲排名——你打弱队效率太低,想上去必须干掉一个强者。
但Spirit 1.6的评测记录表明,它找到了另一个取巧的办法:不是挑弱的打,而是避开强的打,很“聪明”地避开了真正的强敌。
前期,Spirit 1.6和当时榜单第一的DreamZero交手了23次。成绩是17负、4平、2胜——基本打不过。此后,Spirit 1.6不再跟DreamZero对战。双方最后一次PK记录,停在了5月31日。
包括后来登顶的那个模型,Cosmos3-Nano-Policy,5月30日才加入测试。Spirit 1.6跟它,竟然连一次对战记录都没有。
一个在榜单上冲到顶的模型,却从来没有跟真正的前两名正经打过。这不是技术层面做不到公平对战,而是评测策略层面选择性地避开了所有可能输的对手。
到这里,一场刷分操作的全貌已经清晰了:先注册两个自己人账号进评测系统,用这两个账号给自己集中刷高分数据(占总量72%),同时以“随机匹配”为名,绕开所有真正有威胁的对手。
技术上ELO机制还在运转,实际上天梯排名的意义已经被架空了。
榜单狂欢背后,具身智能行业正在经历什么?
当然,这件事最让人不舒服的,不是刷分了,而是刷分和融资之间的时间线。
6月3日,千寻智能发布推文宣布Spirit 1.6登顶RoboArena。同一天,宣布完成15亿元A+轮融资。三个月,累计近50亿元。
在具身智能这个赛道里,技术路径还没收敛,商业化验证还在早期,外部统一的评价体系少得可怜。RoboArena在这样的环境里被迅速推到了前台,成了最直观、最容易被资本听懂的那套“技术证据”。
要知道,榜单排名天然适合写进投资人的尽调材料里。它不是学术论文,它是一串可以直接放进融资PPT里的数字和名次。因此,当排名本身可以直接影响估值和融资节奏的时候,刷榜的动力就不再是学术上的面子问题,而是真金白银在驱动。
但是,RoboArena本身离“权威”还远着。
根据公开资料,RoboArena目前仍是一个学术原型:首个版本在7所学术机构部署,针对7个通用策略完成约600次真机对比,评测硬件绑定在DROID平台(Franka Panda机械臂)上,尚未扩展至其他机器人本体。论文作者也在文中指出,未来需要持续验证其排名结果与真实世界表现的相关性。
也就是说,这个被描述为“世界级权威主榜单”的评测框架,在学术圈尚且属于“有潜力的研究方向”,离行业公认标准还有距离。
但在千寻智能的语境里,这些限定条件全部消失了。RoboArena变成了一个已经封神的“奥林匹克”。很显然,一个还在验证中的学术原型被包装成权威认证,融资故事才讲得通。
时至今日,当刷分被揭穿之后,代价却不只是千寻智能一家的事。
具身智能是中国AI里目前最热的赛道,也是国际关注度最高的赛道之一。这次事件的信息已经传到了海外。当中国具身智能企业的名字和“刷榜”两个字被放在一起讨论的时候,受到牵连的很有可能是整个行业的国际可信度。
更麻烦的是,它还会反向伤害真正在做事的公司。当一家公司靠刷榜拿到近50亿融资之后,那些没有这么做、老老实实在实验室里磨技术的团队,反而会被反复质疑、拷问:“你的排名是真的吗?你怎么证明?”
劣币驱逐良币,就从这里悄然开始、蔓延开来。
如果有人觉得“反正榜单都会被刷,那投入技术有什么用”——这才是这件事最糟糕的后果。
当然,在这场风波里,也有值得说一说的一面。
在Spirit 1.6刷分的那段时间里,WALL-OSS也在全力冲击榜单。它没有找到“定向只测自己”的方法,只能在合规框架里正常打榜,最终被两个刷分账号挤出了竞争序列。作为一家真正遵守规则、按实力去打的团队,却被这个扭曲的评测生态拦在了门外,实属唏嘘。
此外,Cosmos3-Nano-Policy的登顶,是另一个硬核实力的证明。这次官方更新榜单之后,它还在榜上——可见,一个靠合法合规评测打上来的模型,是经得起回溯调查的。
诚然,榜单本身不是假的。有人刷,不代表这个评价体系应该被废弃。但前提是,规则必须能拦住想钻空子的人。
结语
根据最新消息,RoboArena已经出手了。回溯调查、排除了有利益关联的评测数据、重置了评测者准入规则。这是对的,也是必要的。

但这场风波,不应该只以“榜单更新”为终点。
千寻智能的事件之所以值得被认真对待,不是因为它有多罕见,而是因为它可能不是孤例。当一个行业的评价标准本身还不够成熟,而评价结果又可以直接撬动数十亿级别的融资时,钻空子的动力是系统性的,不是某一个人、某一个公司的问题。
靠一份榜单讲故事融资的窗口,到今天还没关上。但通过这件事,至少有了一个可以放在台面上的共识:你拿给你的投资人看的那个“第一”,得是真的。
榜单可以更新,但信任重建,要难得多。
从今天开始,具身智能行业要走的路还很长。
*本文图片均来源于网络
